
Chapter 9: Learning
9.4 Other Types of Learning
Learning Objectives
- Explain latent learning and cognitive maps
- Describe Edward Tolman’s experiment on latent learning
- Explain observational learning and the steps in the modeling process
- Describe the process and results of Albert Bandura’s bobo doll experiment
Introduction to Other Types of Learning

Classical and operant conditioning are responsible for a good bit of the behaviors we learn and develop, but certainly, there are other things we learn simply through observation and thought. Latent learning is a form of learning that occurs without any obvious reinforcement of the behavior or associations that are learned.
According to Albert Bandura, learning can occur by watching others and then modeling what they do or say. This is known as observational learning. There are specific steps in the process of modeling that must be followed if learning is to be successful. These steps include attention, retention, reproduction, and motivation. Through modeling, Bandura has shown that children learn many things both good and bad simply by watching their parents, siblings, and others. What have you learned by observation?
Latent Learning
Although strict behaviorists such as Skinner and Watson refused to believe that cognition (such as thoughts and expectations) plays a role in learning, another behaviorist, Edward C. Tolman, had a different opinion. Tolman’s experiments with rats demonstrated that organisms can learn even if they do not receive immediate reinforcement (Tolman & Honzik, 1930; Tolman, Ritchie, & Kalish, 1946).
Latent learning is a form of learning that is not immediately expressed in an overt response. It occurs without any obvious reinforcement of the behavior or associations that are learned. Latent learning is not readily apparent to the researcher because it is not shown behaviorally until there is sufficient motivation. This type of learning broke the constraints of behaviorism, which stated that processes must be directly observable and that learning was the direct consequence of conditioning to stimuli.
Latent learning also occurs in humans. Children may learn by watching the actions of their parents but only demonstrate it at a later date, when the learned material is needed. For example, suppose that Ravi’s dad drives him to school every day. In this way, Ravi learns the route from his house to his school, but he’s never driven there himself, so he has not had a chance to demonstrate that he’s learned the way. One morning Ravi’s dad has to leave early for a meeting, so he can’t drive Ravi to school. Instead, Ravi follows the same route on his bike that his dad would have taken in the car. This demonstrates latent learning. Ravi had learned the route to school, but had no need to demonstrate this knowledge earlier.
Everyday Connection: This Place Is Like a Maze
Have you ever gotten lost in a building and couldn’t find your way back out? While that can be frustrating, you’re not alone. At one time or another we’ve all gotten lost in places like a museum, hospital, or university library. Whenever we go someplace new, we build a mental representation—or cognitive map—of the location, as Tolman’s rats built a cognitive map of their maze. However, some buildings are confusing because they include many areas that look alike or have short lines of sight. Because of this, it’s often difficult to predict what’s around a corner or decide whether to turn left or right to get out of a building. Psychologist Laura Carlson (2010) suggests that what we place in our cognitive map can impact our success in navigating through the environment. She suggests that paying attention to specific features upon entering a building, such as a picture on the wall, a fountain, a statue, or an escalator, adds information to our cognitive map that can be used later to help find our way out of the building.
Link to Learning
Watch this video to learn more about Laura Carlson’s studies on cognitive maps and navigation in buildings.
Psych in Real Life: Latent Learning
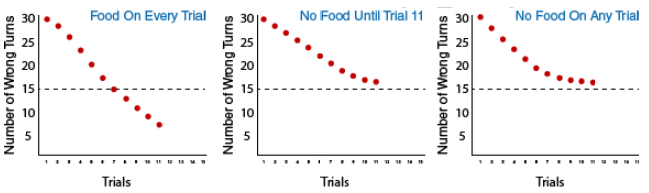
Edward Tolman was studying traditional trial-and-error learning when he realized that some of his research subjects (rats) actually knew more than their behavior initially indicated. In one of Tolman’s classic experiments, he observed the behavior of three groups of hungry rats that were learning to navigate mazes.
The first group always received a food reward at the end of the maze, so the payoff for learning the maze was real and immediate. The second group never received any food reward, so there was no incentive to learn to navigate the maze effectively. The third group was like the second group for the first 10 days, but on the 11th day, food was now placed at the end of the maze.
As you might expect when considering the principles of conditioning, the rats in the first group quickly learned to negotiate the maze, while the rats of the second group seemed to wander aimlessly through it. The rats in the third group, however, although they wandered aimlessly for the first 10 days, quickly learned to navigate to the end of the maze as soon as they received food on day 11. By the next day, the rats in the third group had caught up in their learning to the rats that had been rewarded from the beginning. It was clear to Tolman that the rats that had been allowed to experience the maze, even without any reinforcement, had nevertheless learned something, and Tolman called this latent learning. Latent learning is to learning that is not reinforced and not demonstrated until there is motivation to do so. Tolman argued that the rats had formed a “cognitive map” of the maze but did not demonstrate this knowledge until they received reinforcement.

Now that you’ve learned the design of the study, let’s take a closer look at what happened in the study. The results for the three groups will be shown in these graphs. The graph on the left is for the group that always received food. The middle graph is for the rats that did not received food for the first 10 trials and then, on Trial #11, started to receive food. The graph on the right is for rats that never received food. The red dots indicate how the rats did in each of the three conditions. The Y-axis (vertical axis) indicates how many wrong turns, or errors, the rats in each condition made on average. The X-axis (horizontal axis) shows the different trials. This is the first trial, so none of the rats knew there was food in the food box.

Let’s see how the rats in each group did over the next four trials. Notice all the groups made fewer errors and continue to do so in Trial 4. Now look more closely at trials 4 and 5. Are you starting to see a difference between the groups? Use the dotted line in the middle of the graphs as a reference point for comparing the groups. Which group seems to be getting to the line faster?

Let’s pick up at Trial 7. Notice that the group on the left, which receives food on every trial, continues to improve at a faster rate than the other two groups. These two groups are both performing at the same level and are making about 20 wrong turns on each trial on average. At Trial 10, we are at a critical point in the experiment because things are about to change on the next trial for the rats shown in the middle graph. Something special will happen to this group. Food will now appear in the food box! Of course, they won’t know this until they get there, so the effects of the change should not appear on the next trial. As you can see from the graphs for Trial 11, the groups shown in the middle and right graphs still look the same. The rats in the left group are now making fewer wrong turns than either of the other two groups.
Work It out
Your task here is to predict what is going to happen on Trial 12 for the “no food until Trial 11” group.
Option A: Notice that this result is the same as the “no food on any trial” group. So, if you choose option A, you think that they will not act differently now than they acted on the first 11 trials and they will continue to make a lot of wrong turns.
Option B: This option suggests that they are now motivated to learn the path to the food, but that they will do so in small steps, just as we have seen for all three groups up to this point. Option B says that they are moving in the direction of the “food on every trial” group, but that it will take some extra learning to get there.
Option C: This option says that they already know the path to the food and, now that they are motivated to get there, they will show that they already know just as much as the “food on every trial” group. Their performance on Trial 12 will be the same as the low-error performance of the “food on every trial” group.
So, what happened to the rats in the group that began to receive food at Trial 11? They were immediately able to make their way through the maze without making many wrong turns to get to the food. They made about the same number of errors as the “Food on Every Trial” group! Tolman interpreted this to mean that they had created a mental map of the maze during the first 11 trials…and when they needed to get food, they could find their way to the food box very efficiently!

As we look at trials 13, 14, and 15, notice how the graph for the group of rats on the left –- the ones that received food on every trial — and the graph for the group of rats in the middle — the ones that started receiving food at trial 11 — now look similar. And the rats that never received food continued to make more than 15 errors in each trial on average.

Observational Learning
Previous sections of this module focused on classical and operant conditioning, which are forms of associative learning. In observational learning, we learn by watching others and then imitating, or modeling, what they do or say. The individuals performing the imitated behavior are called models. Research suggests that this imitative learning involves a specific type of neuron, called a mirror neuron (Hickock, 2010; Rizzolatti, Fadiga, Fogassi, & Gallese, 2002; Rizzolatti, Fogassi, & Gallese, 2006).
Humans and other animals are capable of observational learning. As you will see, the phrase “monkey see, monkey do” really is accurate (Figure 1). The same could be said about other animals. For example, in a study of social learning in chimpanzees, researchers gave juice boxes with straws to two groups of captive chimpanzees. The first group dipped the straw into the juice box, and then sucked on the small amount of juice at the end of the straw. The second group sucked through the straw directly, getting much more juice. When the first group, the “dippers,” observed the second group, “the suckers,” what do you think happened? All of the “dippers” in the first group switched to sucking through the straws directly. By simply observing the other chimps and modeling their behavior, they learned that this was a more efficient method of getting juice (Yamamoto, Humle, and Tanaka, 2013).

Imitation is much more obvious in humans, but is imitation really the sincerest form of flattery? Consider Claire’s experience with observational learning. Claire’s nine-year-old son, Jay, was getting into trouble at school and was defiant at home. Claire feared that Jay would end up like her brothers, two of whom were in prison. One day, after yet another bad day at school and another negative note from the teacher, Claire, at her wit’s end, beat her son with a belt to get him to behave. Later that night, as she put her children to bed, Claire witnessed her four-year-old daughter, Anna, take a belt to her teddy bear and whip it. Claire was horrified, realizing that Anna was imitating her mother. It was then that Claire knew she wanted to discipline her children in a different manner.
Like Tolman, whose experiments with rats suggested a cognitive component to learning, psychologist Albert Bandura’s ideas about learning were different from those of strict behaviorists. Bandura and other researchers proposed a brand of behaviorism called social learning theory, which took cognitive processes into account. According to Bandura, pure behaviorism could not explain why learning can take place in the absence of external reinforcement. He felt that internal mental states must also have a role in learning and that observational learning involves much more than imitation. In imitation, a person simply copies what the model does. Observational learning is much more complex. According to Lefrançois (2012) there are several ways that observational learning can occur: You learn a new response. After watching your coworker get chewed out by your boss for coming in late, you start leaving home 10 minutes earlier so that you won’t be late. You choose whether or not to imitate the model depending on what you saw happen to the model. Remember Julian and his father? When learning to surf, Julian might watch how his father pops up successfully on his surfboard and then attempt to do the same thing. On the other hand, Julian might learn not to touch a hot stove after watching his father get burned on a stove. You learn a general rule that you can apply to other situations.
Bandura identified three kinds of models: live, verbal, and symbolic. A live model demonstrates a behavior in person, as when Ben stood up on his surfboard so that Julian could see how he did it. A verbal instructional model does not perform the behavior, but instead explains or describes the behavior, as when a soccer coach tells his young players to kick the ball with the side of the foot, not with the toe. A symbolic model can be fictional characters or real people who demonstrate behaviors in books, movies, television shows, video games, or Internet sources (Figure 2).

Link to Learning
Latent learning and modeling are used all the time in the world of marketing and advertising. This commercial played for months across the New York, New Jersey, and Connecticut areas, Derek Jeter—an award-winning baseball player for the New York Yankees, is advertising a Ford. The commercial aired in a part of the country where Jeter is an incredibly well-known athlete. He is wealthy, and considered very loyal and good looking. What message are the advertisers sending by having him featured in the ad? How effective do you think it is?
Steps in the Modeling Process
Of course, we don’t learn a behavior simply by observing a model. Bandura described specific steps in the process of modeling that must be followed if learning is to be successful: attention, retention, reproduction, and motivation. First, you must be focused on what the model is doing—you have to pay attention. Next, you must be able to retain, or remember, what you observed; this is retention. Then, you must be able to perform the behavior that you observed and committed to memory; this is reproduction. Finally, you must have motivation. You need to want to copy the behavior, and whether or not you are motivated depends on what happened to the model. If you saw that the model was reinforced for her behavior, you will be more motivated to copy her. This is known as vicarious reinforcement. On the other hand, if you observed the model being punished, you would be less motivated to copy her. This is called vicarious punishment. For example, imagine that four-year-old Allison watched her older sister Kaitlyn playing in their mother’s makeup, and then saw Kaitlyn get a time out when their mother came in. After their mother left the room, Allison was tempted to play in the make-up, but she did not want to get a time-out from her mother. What do you think she did? Once you actually demonstrate the new behavior, the reinforcement you receive plays a part in whether or not you will repeat the behavior.
Bandura researched modeling behavior, particularly children’s modeling of adults’ aggressive and violent behaviors (Bandura, Ross, & Ross, 1961). He conducted an experiment with a five-foot inflatable doll that he called a Bobo doll. In the experiment, children’s aggressive behavior was influenced by whether the teacher was punished for her behavior. In one scenario, a teacher acted aggressively with the doll, hitting, throwing, and even punching the doll, while a child watched. There were two types of responses by the children to the teacher’s behavior. When the teacher was punished for her bad behavior, the children decreased their tendency to act as she had. When the teacher was praised or ignored (and not punished for her behavior), the children imitated what she did, and even what she said. They punched, kicked, and yelled at the doll.
Watch It
Watch the following to see a portion of the famous Bobo doll experiment, including an interview with Albert Bandura.
You can view the transcript for “Albert Bandura Bobo Doll experiment.mp4” here (opens in new window).
What are the implications of this study? Bandura concluded that we watch and learn, and that this learning can have both prosocial and antisocial effects. Prosocial (positive) models can be used to encourage socially acceptable behavior. Parents in particular should take note of this finding. If you want your children to read, then read to them. Let them see you reading. Keep books in your home. Talk about your favorite books. If you want your children to be healthy, then let them see you eat right and exercise, and spend time engaging in physical fitness activities together. The same holds true for qualities like kindness, courtesy, and honesty. The main idea is that children observe and learn from their parents, even their parents’ morals, so be consistent and toss out the old adage “Do as I say, not as I do,” because children tend to copy what you do instead of what you say. Besides parents, many public figures, such as Martin Luther King, Jr. and Mahatma Gandhi, are viewed as prosocial models who are able to inspire global social change. Can you think of someone who has been a prosocial model in your life?

The antisocial effects of observational learning are also worth mentioning. As you saw from the example of Claire at the beginning of this section, her daughter viewed Claire’s aggressive behavior and copied it. Research suggests that this may help to explain why abused children often grow up to be abusers themselves (Murrell, Christoff, & Henning, 2007). In fact, about 30% of abused children become abusive parents (U.S. Department of Health & Human Services, 2013). We tend to do what we know. Abused children, who grow up witnessing their parents deal with anger and frustration through violent and aggressive acts, often learn to behave in that manner themselves. Sadly, it’s a vicious cycle that’s difficult to break.
Some studies suggest that violent television shows, movies, and video games may also have antisocial effects (Figure 3) although further research needs to be done to understand the correlational and causational aspects of media violence and behavior. Some studies have found a link between viewing violence and aggression seen in children (Anderson & Gentile, 2008; Kirsch, 2010; Miller, Grabell, Thomas, Bermann, & Graham-Bermann, 2012). These findings may not be surprising, given that a child graduating from high school has been exposed to around 200,000 violent acts including murder, robbery, torture, bombings, beatings, and rape through various forms of media (Huston et al., 1992). Not only might viewing media violence affect aggressive behavior by teaching people to act that way in real life situations, but it has also been suggested that repeated exposure to violent acts also desensitizes people to it. Psychologists are working to understand this dynamic.
Link to Learning
Watch the Crash Course video The Bobo Beatdown for further explanation on observational learning.
Think It Over
What is something you have learned how to do after watching someone else?
Psych in Real Life: The Bobo Doll Experiment
Bandura studied the impact of an adult’s behavior on the behavior of children who saw them. One of his independent variables was whether or not the adult was hostile or aggressive toward the Bobo doll, so for some children the adults acted aggressively (treatment condition) and for others they did not (control condition 1) and for yet other children there were no adults at all (control condition 2). He was also interested to learn if the sex of the child and/or the sex of the adult model influenced what the child learned.
Phase 1 of the Experiment: The Observation Phase
The observation phase of the experiment is when the children see the behavior of the adults. Each child was shown into a room where an adult was already sitting near the Bobo doll. The child was positioned so he or she could easily see the adult.

Phase 2 of the Experiment: Frustration
Dr. Bandura thought that the children might be a bit more likely to show aggressive behavior if they were frustrated. The second phase of the experiment was designed to produce this frustration. After a child had watched the adult in phase 1, he or she was taken to another room, one that also contained a lot of attractive, fun toys and was told that it was fine to play with the toys. As soon as the child started to enjoy playing with the toys, the experimenter said something.
Phase 3 of the Experiment: The Testing Phase
After the child was told to stop playing with “the very best toys,” the experimenter said that he or she could play with any of the toys in the next room. Then the child was taken to a third room. This room contained a variety of toys. Many of the toys were engaging and interactive, but not the type that encouraged aggressive play. Critically, the Bobo doll and the hammer that the model had used in the first phase were now in this new playroom. The goal of this phase in the experiment was to see how the child would react without a model around.
The child was allowed to play freely for 20 minutes. Note that an adult did stay in the room so the child would not feel abandoned or frightened. However, this adult worked inconspicuously in a corner and interacted with the child as little as possible.
During the 20 minutes that the child played alone in the third room, the experimenters observed his or her behavior from behind a see-through mirror. Using a complex system that we won’t go into here, the experimenters counted the number of various types of behaviors that the child showed during this period. These behaviors included ones directed at the Bobo doll, as well as those involving any of the other toys. They were particularly interested in the number of behaviors the child showed that clearly imitated the actions of the adults that the child had observed earlier, in phase 1.
Below are the results for the number of imitative physically aggressive acts the children showed on average toward the Bobo doll. These acts included hitting and punching the Bobo doll. On the left, you see the two modeling conditions: aggression by the model in phase 1 or no aggression by the model in phase 1. Note: Children in the no-model conditions showed very few physically aggressive acts and their results do not change the interpretation, so we will keep the results simple by leaving them out of the table.
| Table 1. Physical aggression results from Bandura’s experiment. |
||||
| Male Model | Female Model | |||
| Boys | Girls | Boys | Girls | |
| Aggression | 25.8 | 7.2 | 12.4 | 5.5 |
| No Aggression | 1.5 | 0.0 | 0.2 | 2.5 |
The story is slightly, though not completely, different when we look at imitative verbal aggression, rather than physical aggression. The table below shows the number of verbally aggressive statements by the boys and girls under different conditions in the experiment. Verbally aggressive statements were ones like the models had made: for example, “Sock him” and “Kick him down!”
Note: Just as was true for the physically aggressive acts, children in the no model conditions showed very few verbally aggressive acts either and their results do not change the interpretation, so we will keep the results simple by leaving them out of the table.
| Table 2. Verbal aggression results from Bandura’s experiment. |
||||
| Male Model | Female Model | |||
| Boys | Girls | Boys | Girls | |
| Aggression | 12.7 | 2.0 | 4.3 | 13.7 |
| No Aggression | 0.0 | 0.0 | 1.1 | 0.3 |
Licenses and Attributions (Click to expand)
CC licensed content, Original
- Observational Learning. Authored by: OpenStax College. Located at: https://openstax.org/books/psychology-2e/pages/6-4-observational-learning-modeling. License: CC BY: Attribution. License Terms: Download for free at https://openstax.org/books/psychology-2e/pages/1-introduction
- Authored by: Patrick Carroll for Lumen Learning. Provided by: Lumen Learning. License: CC BY: Attribution
CC licensed content, Shared previously
- Traquair House Maze. Authored by: marsroverdriver. Located at: https://en.wikipedia.org/wiki/File:Traquair_House_Maze.jpg. License: CC BY: Attribution
- Latent Learning. Provided by: Boundless. Located at: https://www.boundless.com/psychology/textbooks/boundless-psychology-textbook/learning-7/cognitive-approaches-to-learning-48/latent-learning-202-12737/. Project: Boundless Psychology. License: CC BY-SA: Attribution-ShareAlike
- Operant Conditioning. Authored by: OpenStax College. Located at: https://openstax.org/books/psychology-2e/pages/6-3-operant-conditioning. License: CC BY: Attribution. License Terms: Download for free at https://openstax.org/books/psychology-2e/pages/1-introduction
- Latent Learning: Learning Before Doing. Provided by: Open Learning Initiative. Located at: https://oli.cmu.edu/jcourse/workbook/activity/page?context=df3e71c60a0001dc051db622d622b3f7. Project: Psychology. License: CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Psychology. Authored by: OpenStax College. Located at: https://openstax.org/books/psychology-2e/pages/6-4-observational-learning-modeling. License: CC BY: Attribution. License Terms: Download for free at https://openstax.org/books/psychology-2e/pages/1-introduction
- Albert Bandura Bobo Doll experiment. Authored by: kpharden. Located at: https://www.youtube.com/watch?v=Z0iWpSNu3NU. License: CC BY: Attribution. License Terms: Download for free at http://cnx.org/contents/4abf04bf-93a0-45c3-9cbc-2cefd46e68cc@5.48
- Modification and adaptation. Provided by: Lumen Learning. License: CC BY: Attribution
- Observational Learning. Provided by: Open Learning Initiative. Located at: https://oli.cmu.edu/jcourse/workbook/activity/page?context=df3e71c70a0001dc01587dcb723e2002. Project: Psychology. License: CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
learning that occurs, but it may not be evident until there is a reason to demonstrate it
mental picture of the layout of the environment
type of learning that occurs by watching others
process where the observer sees the model rewarded, making the observer more likely to imitate the model’s behavior
process where the observer sees the model punished, making the observer less likely to imitate the model’s behavior
